
Mutation-Based Fault Localization Introduction
A step-by-step guide.

This is a practical explanation of mutation-based fault localization (MBFL). We’ll build intuition with tiny, concrete examples. At the end of this post, I will give a brief example using Python.
Github repo: https://github.com/khaled-e-a/Semantics-Systems-MBFL-1
Concept overview
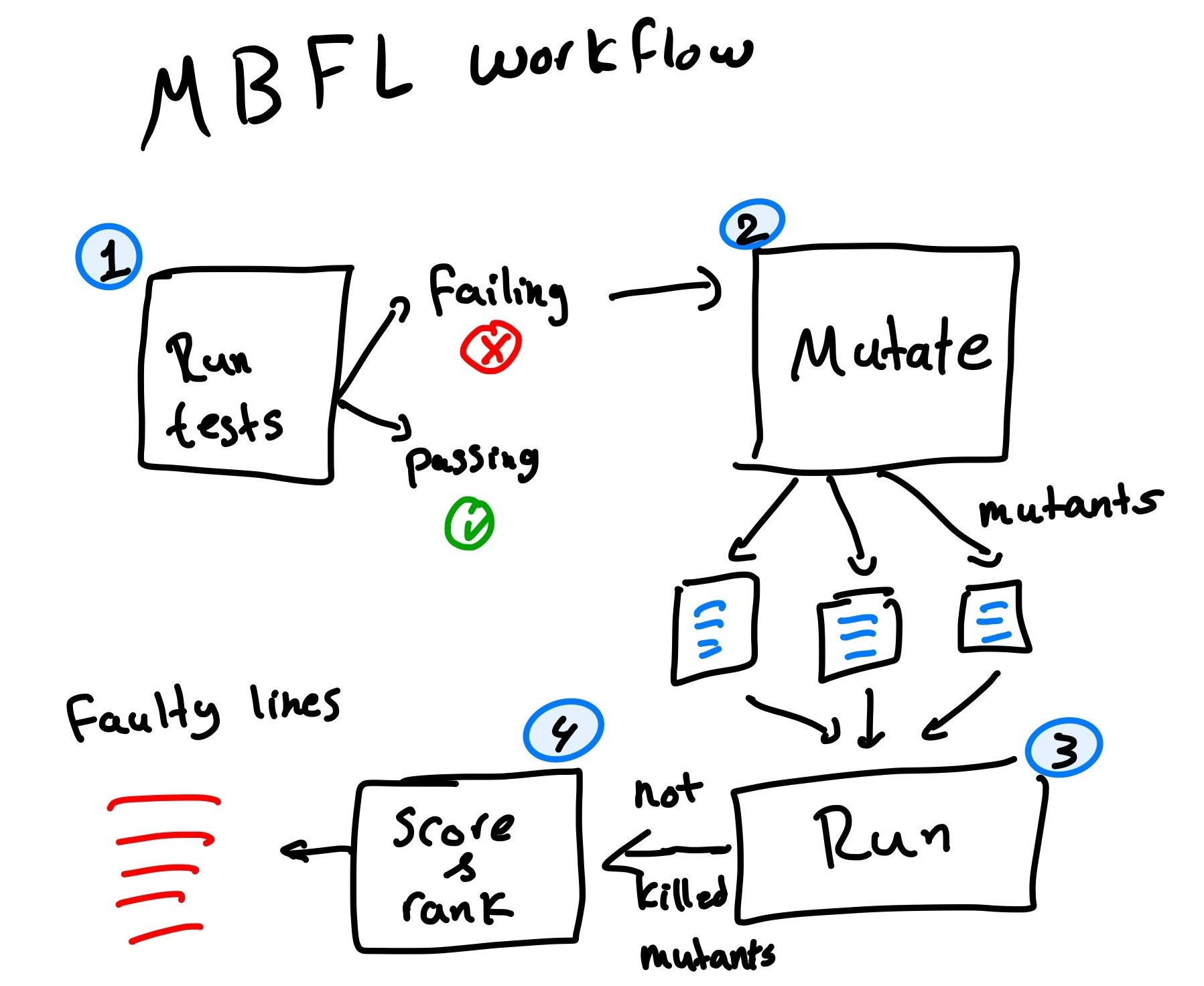
MBFL estimates where a defect resides by performing controlled, single-site edits to the program (creating mutants) and observing how the outcome tests change.
A test kills a mutant if its pass/fail outcome differs from the baseline program.
We then rank code lines whose mutants are killed primarily by failing tests (and rarely by passing ones) as more suspicious.
The output is a list of source lines ordered by likelihood of containing the fault.
Failing tests encode the specific behavioral discrepancy between the program and its specification. If a small, local change at a given code line causes those failing tests to change outcome while passing tests remain stable, that location is likely on or near the execution path of the fault.
In plain terms, failing tests capture the behavior that is currently wrong. If making a small change at a specific line flips those failing tests (and doesn’t break the passing ones), that line is probably close to the cause of the bug. Repeating this at many lines lets us rank locations by how likely they are to contain the fault.
Minimal example: threshold rule
Specification. “Apply a 10% discount when amount >= 100.”
Defect. The implementation uses > instead of >=.
Tests.
T_high:amount = 120→ discount expected (passes at baseline).T_boundary:amount = 100→ discount expected (fails at baseline).
Example mutants.
Replace
>with>=at the threshold comparison.Flip an unrelated boolean operator elsewhere in the code.
Observation.
Mutant 1 changes
T_boundaryfrom fail to pass while leavingT_highunchanged → strong signal for bug.Mutant 2 either does not affect failing tests or fails passing tests → weak or negative signal.
The threshold comparison line, therefore, receives a high suspiciousness score.
Suspiciousness scoring
Let:
F= number of failing baseline tests,Kf(m)= count of failing tests that kill mutantm,Kp(m)= count of passing tests that kill mutantm.
Ochiai1 suspiciousness for mutant m:
High values occur when failing tests change and passing tests do not.
To obtain a line-level score, aggregate mutant scores per line (commonly the maximum per line) and sort lines in descending order.
Practical consideration
When MBFL is effective
At least one failing baseline test exists and captures the defect’s behavior.
The test suite is deterministic and isolates state between tests.
You can run mutants in parallel or restrict the mutation space for scalability.
Common constraints
No failing baseline ⇒ no signal for MBFL.
Excessive mutants may exceed available computing power; use selective mutation and sampling.
Equivalent mutants (no behavioral change) add noise but are expected.
Brief note on the Python repository
Github repo: https://github.com/khaled-e-a/Semantics-Systems-MBFL-1
The reference implementation:
Parses the program AST and records precise mutation sites using
(lineno, col_offset, and comparator index for chained comparisons).Generates one mutant per site via small operator swaps (e.g.,
>=↔>,<=↔<,==↔!=,+↔-,and↔or).Executes the test set on the baseline and on each mutant; a test kills a mutant if its verdict differs from the baseline.
Computes Ochiai per mutant and aggregates to lines (maximum), producing a ranked list of suspicious lines.
Running and reading results
python mbfl_demo.pyYou will see:
Baseline results: confirm there is ≥1 failing test.
Mutant summary: number and location of generated mutants.
Ranking: “Top suspicious lines …” (higher Ochiai ⇒ inspect first). The “via mutants [ids]” list indicates which specific edits produced the line’s maximum score.
Summary
MBFL provides a principled way to prioritize inspection of possibly faulty lines by measuring how failing tests react to small, localized edits. With a focused test that reproduces the defect and a modest mutation budget, the top-ranked lines typically lead quickly to the fault.
R. Abreu, P. Zoeteweij, R. Golsteijn, and A. J. C. van Gemund. A practical evaluation of spectrum-based fault localization. JSS, 2009.