
AI-Driven Development with OpenSpec: A Step-by-Step Walkthrough
Building a budget tracker from proposal to archive, one artifact at a time

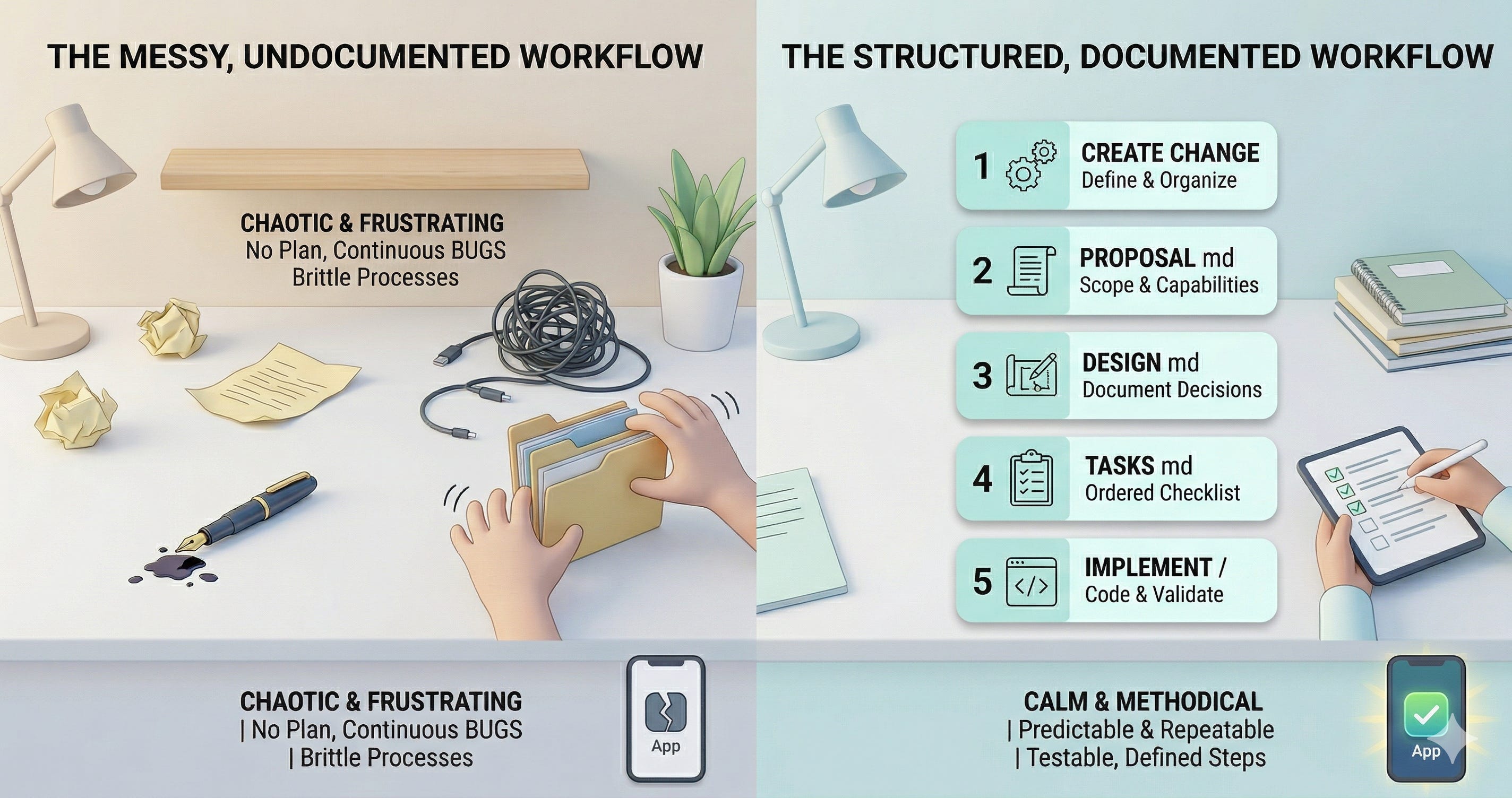
In my previous post, I introduced Spec Driven Development and the four-phase pipeline that keeps AI-generated code predictable and maintainable: Requirement, Design, Implementation, and Validation. I showed the commands and the theory. What I did not show is what it actually feels like to run through the full loop on a real project.
This post does that. We are going to build a local-first budget tracker deployable to web, iOS, and Android using the OPSX workflow. Every command, every artifact, and every decision point is covered. By the end, you will have a repeatable mental model for how OpenSpec structures a project from first idea to archived change.
If you have not read the previous post, I recommend starting there. This one picks up where it left off.

A Quick Recap: What OpenSpec Enforces
Before we dive in, a one-paragraph reminder of why this matters.
OpenSpec does not let you skip ahead. Every change follows a schema, which is a dependency graph of artifacts that must be created in order. The default schema is spec-driven, and it produces four artifacts: a proposal, a design, specs, and a tasks list. Each one unlocks the next. You cannot write tasks until you have a design. You cannot write a design until you have a proposal. The order is the point. It mirrors a traditional SE pipeline and makes it impossible to skip the thinking phase.
The Project: A Local-First Budget Tracker
Here is the brief:
Cross-platform (web, iOS, Android) from a single codebase
Users can set budget categories and sub-categories, each with a monthly value
Users can log daily spending and tag it to a category
Monthly reports show spending vs. budget and net savings
All data is stored locally with no backend and no accounts
Simple enough to build in a session. Complex enough to have real architectural decisions worth documenting.
Let’s run it.
